Table of contents
Open Table of contents
들어가며
대부분의 초기 병행성 관련 오류 연구는 deadlock에 초점이 맞추어져 있었다.
최근의 연구들은 다른 종류의 병행성 버그들 (비교착 상태 버그)을 다룬다.
이번 장에서 다룰 핵심 문제는 다음과 같다.
일반적인 병행성 관련 오류들을 어떻게 처리하는가? 병행성 버그는 몇 가지의 전형적인 패턴을 갖는다. 튼튼하고 올바른 병행 코드를 작성하기 위한 가장 첫 단계는 어떤 경우들을 피해야 할지 파악하는 것.
오류의 종류
첫 번째 질문은 이것이다.
복잡한 병행 프로그램에서 발생하는 병행성 오류들은 어떤 것들이 있는가?
대표적인 오픈 소스 프로그램 4개를 예로 들어 설명한다.
MySQL , Apache, Mozilla, OpenOffice
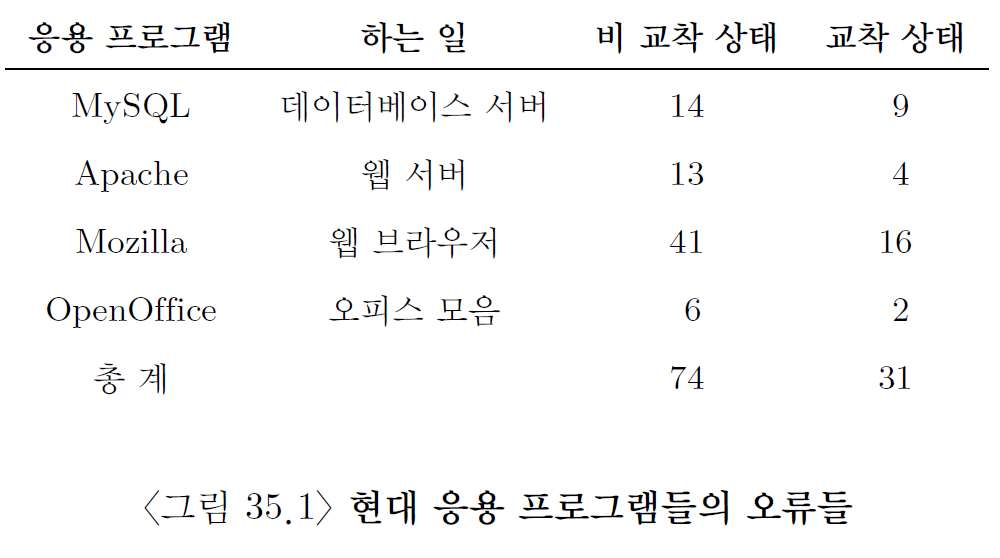 상기 표는 예로 든 병행 프로그램에서의 병행성 오류들을 표로 나타낸 것이다.
비교착 상태와 교착 상태의 오류로 나뉜 것을 알 수 있다.
상기 표는 예로 든 병행 프로그램에서의 병행성 오류들을 표로 나타낸 것이다.
비교착 상태와 교착 상태의 오류로 나뉜 것을 알 수 있다.
비교착 상태 오류
상기 표를 보면 비교착 상태 오류가 병행성 오류의 과반수를 차지한다.
그것들은 어떤 종류일까? 어떻게 발생하는가? 어떻게 해결할 수 있는가?
대표적인 두 종류의 오류인 원자성 위반(atomicity violation) 과 순서 위반(order violation) 오류를 살펴본다.
원자성 위반 오류 (atomicity violation)
 상기 예제는 MySQL에서 발견한 간단한 예제이다.
상기 예제는 MySQL에서 발견한 간단한 예제이다.
thd 자료 구조의 proc_info 필드를 두 개의 딴 쓰레드들이 접근한다.
첫 번째 쓰레드는 그 필드가 NULL인지 검사하고, 두 번째 쓰레드는 그 필드를 NULL로 바꾼다.
만약 다음과 같은 상황을 가정해 보자.
- 첫 번째 쓰레드가 검사를 완료한 후에,
fputs를 호출하기 전에 interrupt가 발생한다. - 이로 인해서, 두 번째 쓰레드가 실행되어, 필드의 값을 NULL로 바꾼다.
fputs는 NULL 포인터 역참조를 하게 되어, 프로그램은 크래시된다.
원자성 위반 오류의 정의는 다음과 같다.
다수의 메모리 참조 연산들 간에 있어 예상했던 직렬성(serializability)이 보장되지 보장되지 않았다. (즉, 코드의 일부에 원자성이 요구됐으나, 실행 시에 그 원자성이 위반됐다.)
어느 부분이 문제일까?
NULL값 검사와 fputs 호출 시 proc_info를 인자로 사용할 때, 원자적으로 실행되는 것 (atomicity assumption)을 가정했다.
근데, 이 가정이 깨진 것이다.
어떻게 해결할까?
락을 추가해, 어느 쓰레드든 proc_info 필드 접근 시, proc_info_lock 락 변수를 획득토록 한다.

순서 위반 오류 (order violation)
 상기 코드에서 쓰레드 2의 코드는
상기 코드에서 쓰레드 2의 코드는 mThread가 이미 NULL이 아닌 어떤 값으로 초기화 됐다고 가정했다.
하지만, 만약 쓰레드 1이 먼저 실행되지 않았다면, 쓰레드 2는 NULL 포인터를 사용하기 때문에 프로그램이 크래시될 것이다. (mThread의 초기값이 NULL이라고 가정했는데, NULL 값이 아닌 다른 값이라 한다면, 더 이상한 일이 발생한다. 임의의 메모리 주소를 접근하는 재앙이… NULL이라고 가정하여 크래시되는 게 낫다.)
순서 위반 오류의 정의는 다음과 같다.
두 개의 (그룹의) 메모리 참조 간의 순서가 바뀌었다. (즉, A가 항상 B보다 먼저 실행되어야 하지만 실행 중에 그 순서가 지켜지지 않았다)
이런 오류를 수정하는 방법은 순서를 강제하는 것이다. 이런 종류의 동기화에는 컨디션 변수가 딱이다.
 쓰레드 간의 순서가 문제가 된다면, 컨디션 변수 (또는 세마포어)를 사용하여 해결할 수 있다.
쓰레드 간의 순서가 문제가 된다면, 컨디션 변수 (또는 세마포어)를 사용하여 해결할 수 있다.
교착 상태 오류
락 L1을 갖고 있는 쓰레드 1 또 다른 락 L2를 기다리는 상황에서, 불행히도 락 L2를 갖고 있는 쓰레드 2가 락 L1이 해제되기를 기다리고 있을 때 교착 상태가 발생한다. 교착 상태가 발생할 가능성이 있는 코드 다음에 나타냈다.
 상기 코드는 교착 상태가 나타날 수 있는 코드를 나타낸다.
이 코드에서는 교착 상태가 발생할 수 있다.
발생하는 경우를 살펴보자.
쓰레드 1이 락 L1을 획득하고 난 후에 context switch가 발생하여 쓰레드 2가 실행한다.
그때, 쓰레드 2 가 락 L2를 획득하고 락 L1을 획득하려고 시도한다.
그러면 교착 상태가 발생한다.
각 쓰레드가 상대방이 소유하고 있는 락을 대기하고 있기 때문에 누구도 실행할 수 없게 된다.
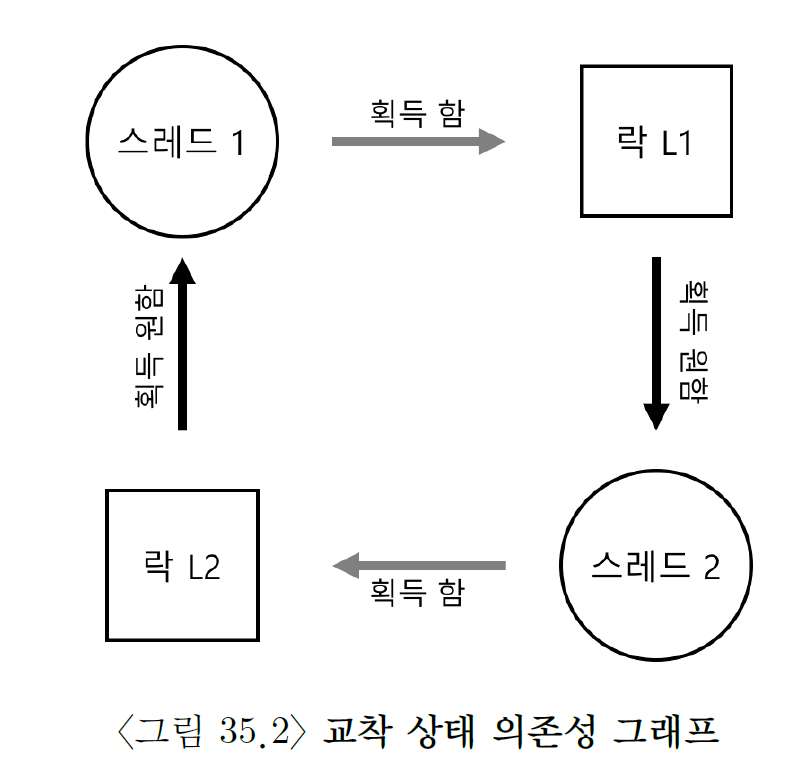
하기에 도표로 나타내었다.
그래프에서 사이클(cycle) 의 존재는 교착 상태 발생 가능성을 의미한다.
이 그림이 문제를 명확히 해줄 것이다.
교착 상태를 방지하기 위해서는 어떻게 코드를 작성해야 할까?
상기 코드는 교착 상태가 나타날 수 있는 코드를 나타낸다.
이 코드에서는 교착 상태가 발생할 수 있다.
발생하는 경우를 살펴보자.
쓰레드 1이 락 L1을 획득하고 난 후에 context switch가 발생하여 쓰레드 2가 실행한다.
그때, 쓰레드 2 가 락 L2를 획득하고 락 L1을 획득하려고 시도한다.
그러면 교착 상태가 발생한다.
각 쓰레드가 상대방이 소유하고 있는 락을 대기하고 있기 때문에 누구도 실행할 수 없게 된다.
하기에 도표로 나타내었다.
그래프에서 사이클(cycle) 의 존재는 교착 상태 발생 가능성을 의미한다.
이 그림이 문제를 명확히 해줄 것이다.
교착 상태를 방지하기 위해서는 어떻게 코드를 작성해야 할까?
교착 상태는 왜 발생하는가?
앞서 본 상황은 손 쉽게 막을 수 있다고 생각할 수 있다. 쓰레드 1과 2가 락을 같은 순서로 획득한다면 절대 발생하지 않는다. 그러면 교착 상태는 대체 왜 발생할까? 한 가지 이유는 코드가 많아지면서 구성 요소 간에 복잡한 의존성이 발생하기 때문이다. 예를 들어, OS를 생각해 보자. 가상 메모리 시스템이 디스크 블럭을 가져오기 위해 파일 시스템을 접근하는 경우가 있다. 파일 시스템은 디스크 블럭을 메모리에 탑재하기 위해 메모리 페이지를 확보해야 하고, 이를 위해 가상 메모리 시스템에 접근한다.
또 다른 이유는 캡슐화(encapsulation) 성질 때문이다.
소프트웨어 모듈화가 개발을 쉽게 하기 때문에, 개발자들은 상세한 구현 내용은 감추라고 교육받는다.
그렇지만, 모듈화와 락은 잘 조화되지 않는다.
전혀 문제가 없어 보이는 인터페이스도 교착 상태를 발생시킨다.
예를 들어, 자바의 Vector 클래스에서 AddAll() 메소드를 생각해 보자.
Vector v1, v2;
v1.AddAll(v2);이 메소드는 멀티 쓰레드에 안전해야 하기 때문에 내부적으로는 v1 에 더해지는 벡터뿐만 아니라 인자로 전달되는 v2에 대한 락도 같이 획득해야 한다.
이 루틴은 v2 의 내용을 v1에 더하기 위해서 임의의 순서로 말한 락들을 획득하는데, 여기서는 v1을 먼저 획득하고 v2를 획득한다고 하자.
어떤 쓰레드가 v2.AddAll(v1)을 거의 동시에 호출하면 교착 상태 발생 가능성이 있다.
이 모든 상황은 호출한 응용 프로그램 모르게 진행된다.
교착 상태 발생 조건
교착 상태가 발생하기 위해서는 네 가지 조건이 충족돼야 한다.
-
상호 배제 (Mutual Exclusion): 쓰레드가 자신이 필요로 하는 자원에 대한 독자적인 제어권을 주장한다. (예, 쓰레드가 락을 획득함.)
-
점유 및 대기 (Hold-and-Wait): 쓰레드가 자신에게 할당된 자원 (예, 이미 획득한 락) 을 점유한 채로 다른 자원 (예, 획득하고자 하는 락) 을 대기한다.
-
비선점 (No Preemption): 자원 (락) 을 점유하고 있는 쓰레드로부터 자원을 강제적으로 빼앗을 수 없다.
-
환형 대기 (Circular Wait): 각 쓰레드는 다음 쓰레드가 요청한 하나 또는 그 이상의 자원 (락) 을 갖고 있는 쓰레드들의 순환 고리가 있다.
이 중 하나라도 만족하지 않는다면 교착 상태는 발생하지 않는다. 먼저 교착 상태를 예방할 수 있는 기술들을 알아 보자.
순환 대기 (Circular Wait)
OSTEP 교재를 그대로 인용했습니다. 딱히 요약할 필요가 없을 거 같아서요.
가장 실용적인 교착 상태 예방 기법은 (그리고 자주 사용되는 방법이기도 함) 순환 대기가 절대 발생하지 않도록 락 코드를 작성하는 것이다. 가장 간단한 방법은 락 획득을 하는 전체 순서 (total ordering) 를 정하는 것이다. 예를 들어, L1과 L2라는 두 개의 락만이 시스템에 존재하면 L1을 무조건 L2 전에 획득하도록 하면 교착 상태를 피할 수 있다. 이 순서를 따르면 순환 대기는 발생하지 않고 따라서 교착 상태도 발생하지 않는다. 물론, 좀 더 복잡한 시스템의 경우, 두 개 이상의 락이 존재할 것이고 전체 락의 요청 순서를 정의하는 것이 어려울 수 있다. (또는, 불필요할 수 있다.) 교착 상태를 피하기 위해 부분 순서 (partial ordering) 를 제공하는 것이 락 획득 구조를 만드는 데 유용할 것이다. Linux의 메모리 매핑 코드가 부분 순서를 제공받아 락을 획득하는 방식에 대한 좋은 예다. 소스 코드의 상단의 주석을 보면 열 개의 서로 다른 그룹으로 묶여 있는 락과 그에 대한 획득 순서를 볼 수 있다. 그 순서에는 ”
i_mmap_mutex전에i_mutex“를 획득해야 한다는 간단한 것부터 좀 더 복잡한 ”mapping->tree_lock전에swap_lock, 그 전에private_lock, 그리고 그 전에i_mmap_mutex“과 같은 순서도 있다. 전체 또는 부분 순서를 제공하기 위해서는 세심하게 락 획득 전략을 설계해야 한다. 더 나아가 순서라는 것은 단순히 관례이기 때문에 숙련되지 않은 개발자들이 이 관례를 무시하고 코드를 개발할 경우, 교착 상태가 발생할 수 있다. 마지막으로 락의 순서를 정의하기 위해서는 코드와 다양한 루틴 간의 상호 호출 관계를 이해해야 한다. 작은 실수라 할지라도 “D” (Deadlock) 로 시작하는 문제를 만날 수 있게 된다.
팁: 락 주소를 사용하여 락 요청 순서 강제하기
do_something(mutex_t *m1, mutext_t *m2*)과 같이 호출되는 함수가 있다고 하자.
이 코드가 m1을 m2 전에 (또는, 그 반대 순서로) 항상 획득한다면 교착 상태가 될 수 있다.
왜냐면, 한 쓰레드가 do_something(L1, L2)라고 호출하고, 다른 쓰레드가 do_something(L2, L1)을 호출할 수 있기 때문이다.
이런 경우를 회피하기 위해, 주소의 값을 사용하여 락 획득 순서를 정하기도 한다.
오름차순이나 내림차순으로 락 획득 순서를 정하면 do_something() 문장에 인자를 어떤 순서로 넣어 호출하든 락 획득 순서는 변하지 않게 된다.

점유 및 대기 (Hold-and-Wait)
점유 및 대기는 원자적으로 모든 락을 단번에 획득하도록 하면 예방 가능하다.

상기의 코드를 보자. 이 코드에서 제일 먼저 prevention 락을 획득하여, 락을 획득하는 과정 중에 쓰레드의 context switch가 발생하는 것을 막고, 결과적으로 교착 상태의 발생 가능성을 차단한다. 쓰레드가 락을 획득하려면 전역 prevention 락을 먼저 획득해야 한다. 딴 쓰레드들이 L1과 L2를 딴 순서로 획득하려고 한다 하더라도 괜찮다. 왜냐면, 그 쓰레드들이 prevention 락을 이미 획득한 후에 나머지 락을 요청하기 때문이다. 이 해법은 문제점이 많다. 먼저와 같이 capsulation과 관련된 사항이다. 필요한 락들을 정확히 파악해야 하고, 그 락들을 미리 획득해야 하기 때문이다. 락이 실제 필요할 때 요청하는 게 아니라, 미리 모든 락을 (단번에) 획득하기 때문에 병행성이 저하되는 문제도 있다.
비선점 (No Preemption)
일반적으로 락을 해제하기 저까지는 락을 보유하고 잇는 것으로 보기 때문에, 여러 락을 획득하는 것에는 문제의 소지가 있다.
왜냐면, 락을 이미 보유하고 있는 채로 다른 락을 대기하기 때문이다.
많은 쓰레드 library들은 이런 상황을 피할 수 있도록 유연한 interface 집합을 제공한다.
trylock() 루틴의 경우 (획득 가능하다면) 락을 획득하거나 현재 락이 점유된 상태니, 락을 획득하기 원하면 나중에 다시 시도하라는 것을 알리는 -1 값을 return한다.
이 interface (trylock()) 를 이용하면, 교착 상태 가능성이 없고, 획득 순서에 영향을 받지 않는 락 획득 방법을 만들 수 있다.

딴 쓰레드가 같은 프로토콜을 사용하면서 락을 다른 순서 (L2 먼저 L1을 그 다음) 로 획득하려고 해도 교착 상태는 발생하지 않는다.
근데, 무한반복(livelock)이라는 새로운 문제가 생긴다.
두 개의 쓰레드가 이 순서대로 시도하기를 반복하면서, 락 획득에 실패하는 것도 가능하다.
두 쓰레드 모두 이 코드를 반복 실행하겠지만, 실제 진척이 있는 것은 아니기 때문에 이름 그대로 무한반복의 상황이다.
이에 대한 해법도 역시 존재한다.
예를 들어, 반복문에 지연 시간을 무작위로 조절하는 것이다.
그러면 경쟁하는 쓰레드 간의 반복 간섭 확률을 줄일 수 있다.
이 해법에 대해 마지막으로 짚고 넘어가야 할 게 있다.
이 해법은 trylock()이라는 방식의 어려운 부분을 다루지 않고 있다.
첫 번째 문제는 capsulation이다.
만약 사용하려는 락이 호출되는 루틴 깊숙한 곳에 존재한다면 처음 부분으로 되돌아가도록 구현하는 것이 쉽지 않다.
만약에 코드가 실행 과정에서 (L1이 아니 다른) 자원을 획득했다면, 그 자원 역시 반납해야 된다.
예를 들어 L1 획득 후 코드에서 메모리 영역을 할당했다면, L2 획득 실패 시에 처음으로 돌아가서 전체 순서를 다시 시작하기 전에 할당받았던 메모리도 같이 반납해야 한다.
하지만, 제한된 경우에만 (예, 앞서 언급했던 자바 벡터 메소드) 이런 접근이 제대로 동작할 것이다. (무슨 말임?)
상호 배제 (Mutual Exclusion)
마지막 예방 기법은 상호 배제 자체를 없애는 방법이다. 일반적인 코드는 모두 임계 영역을 포함하고 있기 때문에 어렵다.
어떻게 해야 할까?
대기없는(wait-free) 자료 구조를 고안한다.
명시적 락이 필요 없는 강력한 하드웨어 명령어를 사용해, 자료 구조를 만들면 된다.
간단한 예제로 다음과 같이 동작하는 Compare-And-Swap 명령어를 가정해 보자.

어떤 한 값을 원자적으로 임의의 크기만큼 증가하는 경우를 생각해 보자.

락을 획득해 값을 갱신한 후에 락을 해제하는 대신, 이 코드에서는 Compare-And-Swap 명령어를 사용해 값에 새로운 값을 갱신하도록 반복적으로 시도한다.
이와 같은 방식을 사용하면, 락을 획득할 필요가 없으며 교착 상태가 발생할 수도 없다. (무한반복은 여전히 발생 가능성이 있긴 한다. 대체 무슨 소리지?)
좀 더 복잡한 리스트에 삽입 예제를 보자.
리스트 헤드에 개체를 삽입하는 코드이다.
 간단한 삽입문을 실행하는 이 코드가 만약 여러 쓰레드에 의해 “동시에” 호출이 되면, race condition이 발생된다.
삽입문 앞뒤에 락의 획득과 해제 코드를 두어 해결하는 방법이 있긴 하다.
이번에는 단순히 Compare-And-Swap 명령어를 사용하여 대기 없이 삽입 명령어를 처리해 보자.
다음과 같은 방법이 있다.
간단한 삽입문을 실행하는 이 코드가 만약 여러 쓰레드에 의해 “동시에” 호출이 되면, race condition이 발생된다.
삽입문 앞뒤에 락의 획득과 해제 코드를 두어 해결하는 방법이 있긴 하다.
이번에는 단순히 Compare-And-Swap 명령어를 사용하여 대기 없이 삽입 명령어를 처리해 보자.
다음과 같은 방법이 있다.
void insert(int value) {
node_t *n = malloc(sizeof(node_t));
assert(n != NULL);
n->value = value;
do {
n->next = head;
} while (CompareAndSwap(&head, n->next, n) == 0);
}상기 코드는 next 포인터가 현재의 헤드를 가리키도록 갱신하고, 새로 생성된 노드는 리스트의 헤드가 되도록 동작하고 있다. 이 코드를 처리하는 도중 만약 어떤 쓰레드가 새로운 헤드를 성공적으로 추가했다면, 이 CompareAndSwap은 실패한다. 쓰레드는 삽입과정을 재시도한다.
스케줄링으로 교착 상태 피하기
어떤 시나리오에서는 교착 상태를 예방하는 대신 회피 하는 게 더 유용할 때가 있다. 회피하기 위해서는 실행 중인 여러 쓰레드가 어떤 락을 획득하게 될 것인지에 대해 전반적으로 파악하고 있어야 된다. 그리고 그것을 바탕으로 쓰레드들을 스케줄링하여 교착상태가 발생하지 않도록 그때그때 보장한다. 예를 들어, 쓰레드 네 개가 프로세서 두 개에서 스케줄링된다고 하자. 그리고 추가로 쓰레드 1(T1)이 L1과 L2 락을, (실행 중일 때 임의의 순서로 획득), T2도 L1과 L2락을, T3는 L2를 필요로 하고, T4는 락이 필요없다고 하자.
 쓰레드들의 락 요청에 관한 정보를 상기 표로 정리할 수 있다.
똑똑한 스케줄러라면 T1과 T2가 동시에 실행되게 되지 않는다면 교착 상태가 절대로 발생하지 않도록 할 수 있다.
그와 같이 스케줄링된 예는 하기와 같다.
쓰레드들의 락 요청에 관한 정보를 상기 표로 정리할 수 있다.
똑똑한 스케줄러라면 T1과 T2가 동시에 실행되게 되지 않는다면 교착 상태가 절대로 발생하지 않도록 할 수 있다.
그와 같이 스케줄링된 예는 하기와 같다.
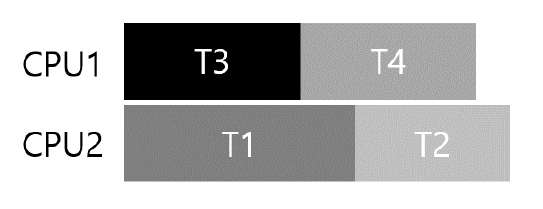 (T3, T1) 또는 (T3, T2) 끼리는 겹쳐서 실행이 되도 괜찮다.
T3는 절대로 교착 상태를 유발하지 않는다.
왜냐면, 단 하나의 락만 필요하기 때문이다.
또 다른 예를 보자.
이번에는 하기의 표에 나온 것처럼 동일한 자원 (마찬가지로 L1과 L2 락 사용) 에 대해 경쟁이 심해졌다고 해 보자.
(T3, T1) 또는 (T3, T2) 끼리는 겹쳐서 실행이 되도 괜찮다.
T3는 절대로 교착 상태를 유발하지 않는다.
왜냐면, 단 하나의 락만 필요하기 때문이다.
또 다른 예를 보자.
이번에는 하기의 표에 나온 것처럼 동일한 자원 (마찬가지로 L1과 L2 락 사용) 에 대해 경쟁이 심해졌다고 해 보자.
 쓰레드 T1, T2, 그리고 T3가 실행 중 어느 시점에 모두 L1과 L2 락을 획득하는 경우를 예로 들어 보자.
그런 경우에 교착 상태가 절대로 발생하지 않도록 하는 가능한 스케줄링은 하기와 같다.
쓰레드 T1, T2, 그리고 T3가 실행 중 어느 시점에 모두 L1과 L2 락을 획득하는 경우를 예로 들어 보자.
그런 경우에 교착 상태가 절대로 발생하지 않도록 하는 가능한 스케줄링은 하기와 같다.
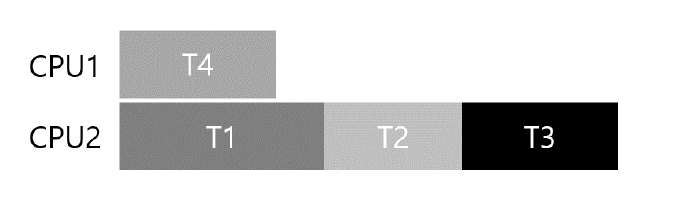 이와 같이, 정적 스케줄링은 T1, T2, T3가 모두 한 프로세서에서 실행되도록 보수적인 방법을 택하기 때문에, 전체 작업이 끝나기까지 상당히 오랜 시간이 걸리게 된다.
병행이 가능할 수도 있겠지만, 교착 상태가 발생할 수 있기 때문에, 그렇게 할 수 없으며, 어쩔 수 없이 성능 하락을 수반한다.
유명한 예로 다익스트라의 은행원 알고리즘이 있다. (그러나 상당히 제한적인 환경에서만 유용하다. 예를 들어 전체 작업에 대한 모든 지식을 알고 있는 임베디드 시스템에서 작업을 실행 하면서 필요한 락을 획득하는 경우이다. 더 나아가 이러한 방법들은 두 번째 예에서 본 것과 같이 병행성에 제약을 가져 올 수도 있다. 때문에 스케줄링으로 교착 상태를 회피하는 것은 보편적으로 사용되는 방법은 아니다.)
이와 같이, 정적 스케줄링은 T1, T2, T3가 모두 한 프로세서에서 실행되도록 보수적인 방법을 택하기 때문에, 전체 작업이 끝나기까지 상당히 오랜 시간이 걸리게 된다.
병행이 가능할 수도 있겠지만, 교착 상태가 발생할 수 있기 때문에, 그렇게 할 수 없으며, 어쩔 수 없이 성능 하락을 수반한다.
유명한 예로 다익스트라의 은행원 알고리즘이 있다. (그러나 상당히 제한적인 환경에서만 유용하다. 예를 들어 전체 작업에 대한 모든 지식을 알고 있는 임베디드 시스템에서 작업을 실행 하면서 필요한 락을 획득하는 경우이다. 더 나아가 이러한 방법들은 두 번째 예에서 본 것과 같이 병행성에 제약을 가져 올 수도 있다. 때문에 스케줄링으로 교착 상태를 회피하는 것은 보편적으로 사용되는 방법은 아니다.)
발견 및 복구
이 부분도 그냥 교재 내용을 그대로 넣었습니다. 굳이 요약할 필요가 없을 거 같아서요.
마지막 전략은 교착 상태 발생을 허용하고, 교착 상태를 발견하면 복구토록 하는 방법이다. 예를 들어 운영체제가 일 년에 한 번 멈춘다고 했을 때 재부팅을 하고 기분 좋게 (또는 우울하게) 다시 작업을 처리하는 식이다. 교착 상태가 아주 가끔 발생한다면 이런 방법도 꽤 유용하다. 많은 데이터베이스 시스템들이 교착 상태를 발견하고 회복하는 기술을 사용한다. 교착 상태 발견은 주기적으로 실행되며 자원 할당 그래프를 그려서 사이클이 생겼는지를 검사한다. 사이클이 발생하는 경우(교착 상태인 경우) 시스템은 재부팅되어야 한다. 자료 구조에 대한 복잡한 복구가 필요할 경우, 사람이 직접 복구 작업을 수행할 수도 있다.